Software Defined Waffle with a gitops topping
Shortcuts
Over the last two years or so, I have been on adventure with Data Centre Infrastructure renewal. As past posts may allude to, ACI was a big part of what we did, but before anyone gets all dogmatic about it, know that we didn’t go “All in” with that one product, since I personally don’t subscribe to the “DC Fabrics cure all ills” mantra.
CLOS fabrics and the various approaches to overlays within them are great at providing stable platforms with predictable properties for speed, latency and scale. Unsurprisingly, they go on to do a great job in server farms that can make the best use of that flexibility. During recent conversations on DC refresh, our Arista friends have been extremely keen to try and get us to run our Internet BGP border on the fabric as well. The 7280SR2K can handle 2M routes in FIB they say, just lob stuff into a VRF, bit of policy and voila. Yeah.
Just because you can, doesn’t mean you should.
In the end we blended a lot of the old school Block model, with elements of new tech, and a heavy dose of gitops for config management and deployment. At a high level, the layout is something like this.
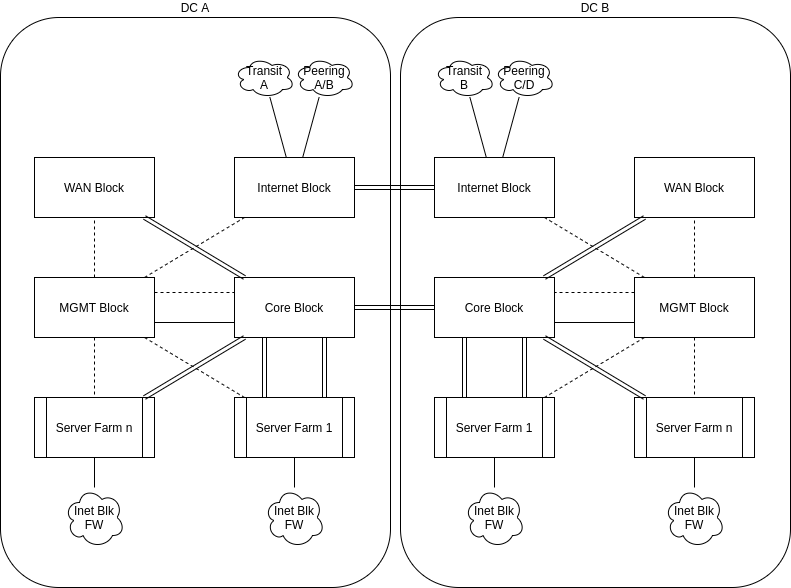
In general, the idea was that in each position, the equipment selected would do one job and do that job well. As the old saying goes, when you try to be the jack of all trades, you end up being the master of none.
There are Pros and Cons to this idea, with many of them coming back to the premise that the segmentation means a clean, simplified deployment strategically, but operationally leaves you with much more hardware to buy and maintain.
As Russ White famously says, its not about right and wrong, its about the trade-offs and what works for your environment.
For us, our key driving aim was a stable, scalable environment. Our experience of early versions of ACI had taught us that SDN as a concept delivers significant benefits of operational efficiency, with equal parts risk. The faster and easier it is to make a change, the faster and easier it is to break everything. To solve that risk vs reward conundrum, we turned to automation. Its harder to break things if you have a structured, known good template that you feed with the variables. Its also quick to send that out to multiple places with an orchestrator like Ansible Tower.
It also gave us our own experience in the technology sector hype-cycle. Software Defined hype is everywhere, and the cycle is the same every time.
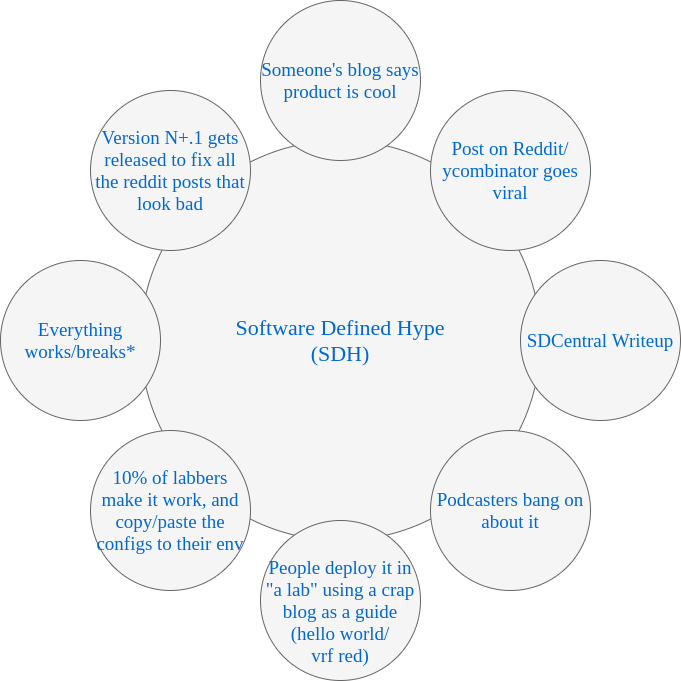
* delete as appropriate.
Throughout each iteration of that loop, more people make it past that 10% completion rate, and end up customers of said product. Ultimately as things get through a number of version iterations the products stabilise and the amount of blogs explaining how it works improve and the amount of people who get to try it out successfully goes up exponentially.
ACI is a good example of this awkward cycle (we were a very early customer back in v1.1 days). That first deployment was “stable” in so far as what you configured would mostly work fine, but it was so hard to configure, you didn’t do that very often, and it rarely worked first time. If and when it did break, you would be on to TAC and you would have to wait for one of the maybe 10 people worldwide who knew how it worked. Version 2 was a marked improvement, making it more accessible as an engineer, but version 3 was a very stable product. We, as veteran operators are only now planning our move to Version 4, and whilst version 5 was just released, the rule of thumb is to only ever run the Long Term Support (LTS) versions which are the .2 releases (3.2 is currently community recommended unless you need 4.2 for the new fancy FX2 switches).
The same is true of SDWAN as it lives today. It started off with DMVPN in a frock, and had a few cycles of integrations with various things like SaaS in the cloud and whatnot to now, essentially losing its product status and becoming a feature in your edge device, or in some cases, becoming your new edge device.
In the first versions it was clunky and whilst the outcome was what you signed up for, the effort and the risk entailed to get there was not really well understood. As early Viptela users (pre-Cisco acquisition), we know full well how the sausage is made. Nowadays they’re almost entirely turnkey in terms of “time to value”, but to get the very best you still need to care and feed more than you expected when you signed up.
Ultimately, across the enterprise sector, getting into these new technologies are seen as a must in order to survive. That urgency to get into the tech leaves a lot of teams being reactive, rather than proactive and that back foot setting means you don’t get time to do proper due diligence, planning and or training. At which point this turnkey capability becomes a double-edged sword. This is why when I see the “network engineers must be programmers” I am so deeply conflicted. Yes, you need to have scripting knowledge, because, yes, the only way to keep up is to automate. Sadly, we don’t have the time to do that well; hell we don’t even have time to learn our own discipline well half the time, let alone a whole other one. This is the danger of that Copy/Paste bubble in the hype cycle. When we dont have time to be an expert, we ask another expert for help - its human nature. In enterprise that takes one of two forms - Consultancy or Plagiarism. In my opinion, neither are better or worse than the other, since they result in the same outcome - people don’t know how things work.
So here is where I come to the meat of this post. Having done quite a few of these deployments over this last few years, I have experienced both ends of the spectrum in terms of under-preparedness and or nonchalance towards the level of effort required over time, and at the other end, excessive automation and overly officious policies about use thereof.
Being able to look back now I can say without any question that investing time in modeling your consuming environment logically, is time well spent x1000. That is to say, you should spend at least one week in a room with a whiteboard talking about how your workloads will attach to the network, both in abstractions, and then down to the lowest detail possible. This time spent now will allow you to at least build solid process workflows for manual admin of the platform, and at best allow you to script it so with minimal input, you get a reliable, repeatable output. Always strive for the latter, but accept that your skills might not permit for that now, and ensure you have no less than the former fully documented, and such manual processes are peer reviewed against that document, and change controlled.
Perhaps contentiously, one of my biggest regrets in our first deployment was being very anal about “Automation only” in change management. We wrote it in stone with blood that no person would manually configure the fabric from the GUI. All changes were done in YAML and pushed out via Ansible Tower. I had listened to so many people who were already in this hallowed place and every one of them regretted every manual change, since back-filling the automation later was so awkward.
The issue that I had was that lack of flexibility, coupled with engineers that were still finding their feet with automation, led to resentment from some, and made our deployments take longer because those people that didn’t universally understand the approach, either avoided it or couldn’t find time to do their work among their other tasks.
I can tell you that back-filling that automation is indeed hard, but its not impossible, and it is unreasonable to automate all the things in day 1. Try to do that and day 1 will never come, and you’ll never deploy anything.
My best advice to people now is to use that modeling information you created to pick your battles, and automate tasks that you know you will repeat at some regular interval. Find the breakeven point that works for your business in terms of effort to automate and iterations of execution - we said anything we do at least once a week. You then set a very strict change process around the manual tasks outside of that range, so that when you do need to back-fill automation, it shouldn’t be destructive.
If you’re not sure how to do this, XKCD has you covered:
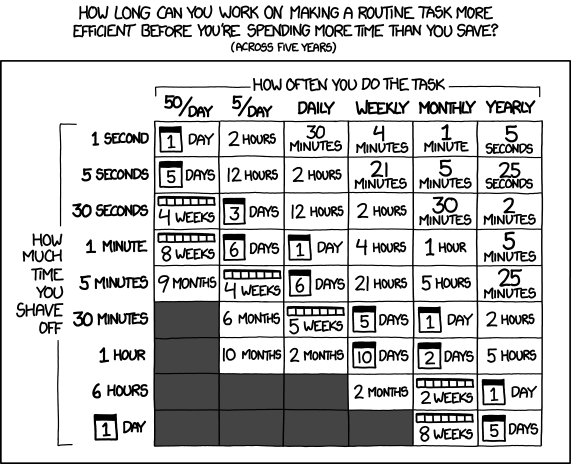
Choosing the framework to base your automation around is probably another thing you should spend a respectable amount of time on, and most critically, ONLY make a decision following a completed, successful POC. I can look at the market today and see perhaps 20 products that claim to be end to end orchestrators and of those maybe 15 are very pricey things that expect you to “buy in” to effectively being your CMDB. That is fine, but you’re almost certainly vendor locked in at both a platform and a fabric level thereafter. Good luck in yr3 with your maint renewal as well. Of the remaining ones, Tower is top of the pile since its very generic, but you’ll spend a lifetime in YAML - be forewarned. VRO is probably next assuming you are in a virtualised world based on VMware; its very good, but very clicky clicky - make sure you have a spare keyboard and mouse. Atlantis is good if you have a very modern platform with terraform modules in the wild and have to co-exist with the public cloud.
Ultimately we learned the hard way that its not realistic to aim for a single tool for changes - there are many tools out there with different pros and cons. As we matured in our approach, we have been moving more and more towards Pipelines in git, which in our world means gitlab-ci.
Today, what we found to work well is to have gitlab host all our process code/scripts, and then pipelines execute on a change of that state to then chain together ansible, terraform, python code, and or random rest calls, such that a workflow gets from change request, to delivered via a merge request which is appropriately approved by leadership, and a change execution process which doesn’t require platform specific compromises. The pipeline executes the right tool for the job, and the qualified engineers can maintain their pieces and parts, leveraging their focused expertise, and not necessarily have to be a full stack engineer genius unicorn.
Finally, the elephant in the room has to be where you host your state. When we started with the gitops adventure, we did not have a business wide CMDB. We had a bunch of localised ones, but we didn’t have one central thing. We considered what we should do about this, but very quickly it spiraled from something we could use to something we needed everyone else to use too. In parallel a wider project was created to solve this problem, and so we resolved to use YAML in git for our state. Two years later and our git repos are huge, and unruly. It was a bad call since it didn’t scale. That project to backfill a CMDB across a multi billion dollar company is not really much further forward either, so we are now building out a netbox based solution for our Infrastructure operations. Only time will tell if that was a good idea or not, but if you find yourself at the beginning of a big deployment, build from the start with a CMDB, even if you don’t use that to trigger your automation like Netbox was designed to do. Have the state somewhere relational and programmatic. If you don’t you’ll regret it just like me.