ACI: Initial Design Considerations
ACI brings with it many different constructs for operating networks, some of which have analogous equivalence with classical networking, some of which are literally bat-poop crazy.
As per usual, you can find lots of resources on how to structure ACI fabrics elsewhere, i’m not going to waste time on what you can do and focus on what I am going to do (roughly).
The below Image was unceremoniously stolen from Cisco themselves, in the critical read ACI Fundamentals
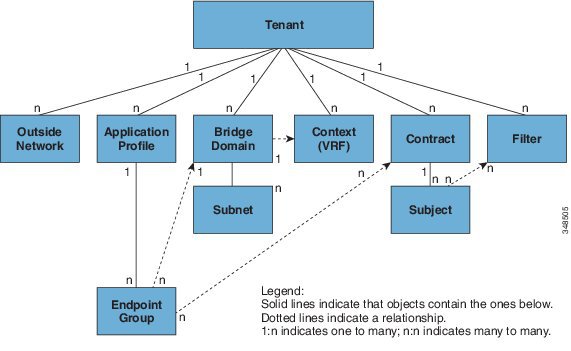
Tenants⌗
These are the first and biggest of the Russian Dolls (under the fabric itself). Everything is contextualised within a tenant. To explain this better lets quickly look at the bottom up. a service offering (like a web server or a database) exists in the physical or virtual world, and is our border between the application and the network. The connection point for these is called an EndPoint Group (EPG). An EPG lives within a Bridge Domain. This is kind of like a PVLAN enabled VLAN, but more cleverererer. A Bridge domain is assigned to a tenant. Going the other way, a Tenant may have more than one Bridge domain, but those bridge domains can only be assigned to one tenant. and EPG can only be assigned to one Bridge Domain. So this is why we start at the tenant.
For me, the vast majority of my applications are 3 tier webapps with presentation, application and data layers. Each of these have vlan segmentation with firewalls operating as the gateways. We operate rule of least priviledge and only permit explicit traffic. Each of these applications has a cookie cutter set of environments for development, testing, non production, beta testing and then production active/standby. These applciations have some pretty strong interdependencies, and borrow liberally from each other in true object oriented fashion, therefore we cannot fully isolate them on an east west level (app to app within environment classification), but we certainly can (indeed should) isolate them environment to environment (north east/west, south east/west). We would hate to see a silly misconfig mean that a beta env host tainted a pre-prod host, or worse, dev/test hit production.
Therefore, my plan is to make each region’s environment a tenant, e.g. UKProd, IEDev etc, etc…
Bridge Domains⌗
Bridge Domains are kind of like a fabric wide L3 enabled switch - you can have classical L2 ports with a VLAN, you can have routed access via subinterfaces and you can use VRFs to handle L3 segmentation. They are logical constructs to enable a collection of devices (in one or more EPGs), to talk to one another and the rest of the fabric. In Pure ACI mode, they are a distributed default gateway across all the leaves that contain connected nodes in that EPG. That is an important distinction to note. If you have an EPG with two webservers in, and they are connected via Leaf 1 and 3, the Bridge Domain announces the gateway address(es) for that EPG only on those Leaf switches. If your workload moves (due to latency/service outage/VMotion), then the gateway is announced on whatever leaf the device pops up on. It even trombones the traffic between new and old leaf in the seconds during the announcement change, which is nice.
Therefore in each of my new regional environment tenants I will be installing at least two types of Bridge Domain; a native ACI BD, and legacy uplink DBs for mapping the old VLANs over to the ACI world (for interop during migration).
Contexts⌗
If bridge domains were loosely related to L2 services, Contexts, are loosely related to L3 services. This is the upstream route aggregation point within the tenant for multi L3 interaction. Packets going at L3 between EPGs will use this to establish where and how the packets move about. Again, you can have many of these to provider further segregation if you so desire (maybe having one as a sin bin during blue/green deployments), but so far i’m struggling to find a user case for more than one in my world - that may change I spose…
Contracts⌗
I expect this to be the busiest area of ACI for me, and that I will spend many many hours crafting these to restore endless annoying flows that were previously permitted without too much resistance from IT. Many others describe contracts in their simplest form as a contract is a ACL for a stateless firewall. I think that muddies the waters far too much. People see firewall, and that gives contracts far to high a standing in Engineers minds. Packets exiting the EPG into the fabric do that via a corridoor with lots of locked doors. If your packet has the right key, it can open the door and enter the fabric. If it has no key, it doesnt get out of that corridoor. The doors have auto closers, and the return path has a handle, and no key is required.
Put another way, its stateless since you only enter the fabric when you have an explicitly defined contract. We secure the fabric at its edge, meaning we don’t have to worry about permitting the egress elsewhere in the fabric, and the return traffic is permitted via the same contract (where the same is true for no need to filter egress traffic to the original source). Since we use VXLAN overlays, there is only one logical hop in the fabric, as EPG in/egress interfaces are effectively mapped together with point to point tunnels.
I know one guy that described contracts as the prefix tunnel matching ACLs in IPSEC - that is also not a bad analogy.
I will have MANY contracts in my library, and these will be re-used extensively throughout the environment.
Service Chaining⌗
This one isn’t on the policy model per-se (its part of the contracts), but its a critical component in the infrastructure. For me this fits into two sections today;
Firewalling⌗
We use Cisco 5585X firewalls with SSP modules. Since ACI will be doing the “simple” ACL work of permit/deny specific applications, my firewall will have a more engrained role in the service chain - its primary reason for existence is Deep Packet Inspection (DPI), Application fingerprint validation and IPS. Therefore, we will be inserting the ASA-CX modules into each contract to validate that the traffic permitted in the contract is what we thought it was, and that the data flowing in the payload isn’t something that we don’t like. Since the firewall isnt allocating lots of memory and cycles to stateful tracking and ACL work, this is hopefully going to be a low latency inspection.
Load Balancing⌗
The Load balancing workload is of huge importance when you work with web services as we do. We have hundreds of VIPs balancing traffic over thousands of hosts. What makes little sense to people when you start with ACI, is how you do that load balancing from within a contract between two EPGs. For me, the concept remains close to what we do already.
In my world I will configure the F5 with a single arm, operating source NAT on the egress to the node. The service profile will sit behind the external firewall service profile, therefore after the first DNAT (Public IP > DMZ IP hosted on F5). The f5 then takes over, mapping the VIP to a static list of Pool members, who are in the EPG. The f5 source NATs the traffic out to the required node, which is where the contract target exits.
As a side-note, please can f5 sort their system to integrate better and just have an EPG name as the VIP target. ;)
Outside Networks⌗
This one remains on the fence for me. I use OSPFv2 (iGP), and BGP (eGP) in my DCs already. I could retain those, and have a small-ish amount of pain. Or I could stand up iBGP between my aggregation points and ACI, making me pure BGP. My head says least amount of change possible. My heart says pure BGP.
Effectively you assign some ports to the outside L2/3 EPGs (depending on your needs), and join those ports to the iGP in use already. You then setup a route reflector on one Spine, to ensure the full fabric knows how to reach outside L3 addresses. It is recommended to have raw interwebs come in on a separate port and run iBGP on that. This is because internet facing connections land in ACI in a special EPG to enable simple contract and service chaining management. More to come on this from me…
So there we have my quick list of things that I will be working on for the next month. My goal is to have all the standup operations be 100% automated with Python and the acicobra module. This will be revision controlled in our internal gitlab, and so hopefully, and stupid mistakes I make can be burned and restored within about 5 mins if need be - this alone is a really handy thing - being able to (albeit non-gracefully) roll back to a known good state within an acceptable P1 period.
I will review this at the end of the initial testing period and see how well I did!